Random Forest Model Analysis
The second approach in our data analysis involved utilizing a Random Forest model. This method is highly regarded in the industry for customer retention/churn prediction due to its robust handling of feature importance and non-linear relationships.
The model's tuning simplicity further contributed to achieving a more accurate result.
Data Cleaning
Following the procedures from our initial model, we cleaned the data by encoding categorical variables like 'Gender' and 'Geography' into binary columns. We also refined our dataset by excluding features deemed less important during the data training phase.
Model Training and Results
Incorporating the Standard Scaler method, we aimed to enhance the model's performance further. The parameters used for the Random Forest Classifier were:
- n_estimators: 25
- Random State: 78
The model achieved an accuracy score of approximately 85.63%.
Displayed below are the Confusion Matrix and Classification Report which elucidate the model's predictive capability:


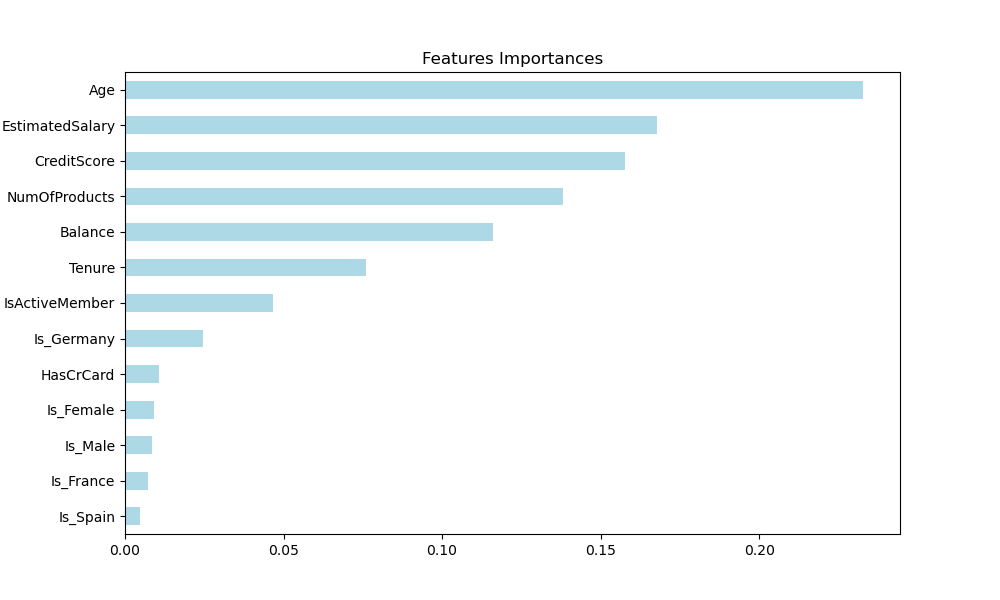
Findings
The Random Forest model showcased improved accuracy, corroborating its industry favorability for the given dataset. Notably, features such as 'Age' and 'Estimated Salary' held more significance in prediction. Although precision and recall for class '0' were high, class '1' performance was not as strong. This insight, along with the distribution of false positives in the confusion matrix, led us to explore another model, XGBoost, to refine our predictive accuracy further.